Chapitre V: La Carte des Algorithmes de Machine Learning
Par M. Royce
- 7 minutes de lecture - 1452 mots« Un jour, alors que je parcourais les vastes couloirs de la Bibliothèque des Prédictions, je suis tombé sur une carte ancienne. Une carte pas comme les autres… Une carte capable de révéler les chemins vers les prédictions les plus justes et les plus incroyables. Aujourd’hui, je vous invite à plonger avec moi dans cette exploration magique : la Carte des Algorithmes de Machine Learning. »
Table des matières
- Une carte à trois chemins
- Premier chemin : L’apprentissage supervisé
- Deuxième chemin : L’apprentissage non supervisé
- Troisième chemin : L’apprentissage semi-supervisé
- Conclusion : Le choix du chemin
Dans les profondeurs des données se cache une force mystérieuse, capable de transformer des informations brutes en connaissances précieuses : c’est le Machine Learning. Mais que se cache-t-il réellement derrière ce terme, souvent évoqué dans le monde des sciences des données ?
Le Machine Learning, ou apprentissage automatique, est un domaine de l’intelligence artificielle où les machines apprennent à partir de données. Comme un apprenti sorcier, une machine s’entraîne avec des exemples pour identifier des motifs cachés et faire des prédictions. Contrairement aux sortilèges traditionnels où chaque geste doit être appris à la perfection, ici, l’algorithme améliore ses compétences avec l’expérience.
Une carte à trois chemins
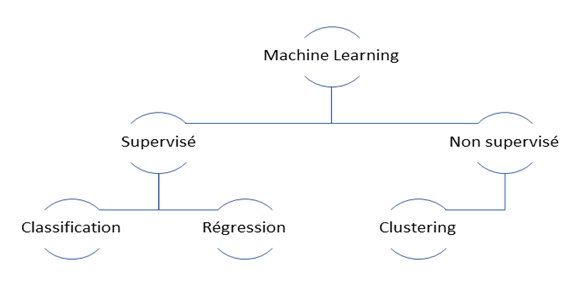
Dans le royaume des algorithmes de machine learning, il existe trois grands chemins tracés par des générations de magiciens des données : l’apprentissage supervisé, l’apprentissage non supervisé et le mystérieux apprentissage semi-supervisé. Comme toute carte magique, chaque chemin mène à des trésors différents.
-L’apprentissage supervisé : Imagine un apprenti sorcier qui reçoit des indices clairs à chaque étape, une sorte de guide pour chaque décision. Il sait toujours si sa prédiction est correcte, car il a des exemples pour s’entraîner.
-L’apprentissage non supervisé : Ici, le sorcier est laissé seul face aux mystères des données. Il doit chercher des motifs cachés, comme un détective dans le brouillard. Personne ne lui dit s’il a raison ou tort, il doit déduire par lui-même.
-L’apprentissage semi-supervisé : Un juste milieu, où parfois un indice est donné, et d’autres fois, il faut suivre son instinct. C’est un équilibre entre les deux mondes.
Tu l’auras compris, ici le sorcier représente la machine(le modèle) qui apprend.
Premier chemin : L’apprentissage supervisé
Imagine un jardinier qui souhaite savoir si une plante est une rose ou un tournesol. Chaque plante qu’il a dans son jardin est déjà étiquetée : les roses d’un côté, les tournesols de l’autre. Le jardinier observe donc les caractéristiques de ces plantes étiquetées, comme la taille, la couleur des pétales, et la forme des feuilles, pour créer un guide. Lorsqu’il reçoit une nouvelle plante sans étiquette, il peut alors utiliser ce guide pour décider s’il s’agit d’une rose ou d’un tournesol.
L’apprentissage supervisé fonctionne de la même manière : nous fournissons à l’algorithme des données étiquetées, c’est-à-dire que chaque observation est accompagnée d’une réponse correcte. L’algorithme “apprend” à partir de ces exemples et peut ensuite faire des prédictions sur de nouvelles données.
Exemples concrets :
Reconnaissance d’images : Identifier si une image représente un chat ou un chien en analysant des images étiquetées de chats et de chiens.
Prédiction du prix d’une maison : Utiliser des caractéristiques comme la taille, le nombre de chambres, et l’emplacement de maisons vendues pour prédire le prix d’une nouvelle maison.
Quelques Modèles d’apprentissage supervisé :
Régression linéaire : Prédit des valeurs continues, comme le prix d’une maison ou la température future.
Arbre de décision : Prend des décisions en fonction de questions successives, comme “Cette plante a-t-elle des épines ? Si oui…? Si non…?”.
K-Nearest Neighbors (KNN) : Compare une nouvelle donnée avec les données les plus proches d’elle pour prédire une réponse.
Forêt aléatoire : Un ensemble d’arbres de décision qui travaillent ensemble pour prendre une décision plus robuste.
Deuxième chemin : L’apprentissage non supervisé
Imagine un archéologue qui découvre un ancien site rempli de fragments de poteries. Personne ne lui a donné d’instructions ou d’indices sur la provenance ou l’époque de ces poteries. Sa tâche est d’essayer de regrouper les fragments qui se ressemblent, peut-être par forme, couleur ou type de matériau. Il ne sait pas à l’avance ce qu’il va trouver, mais en examinant attentivement ces fragments, il peut commencer à identifier des motifs et à les classer en différentes catégories.
L’apprentissage non supervisé fonctionne de la même façon : aucune donnée n’est étiquetée. L’algorithme explore les données et essaie de trouver des structures ou des regroupements cachés, comme un détective qui tente de résoudre une énigme sans aide.
Exemples concrets :
Segmentation de clients : Une entreprise souhaite regrouper ses clients en fonction de leurs comportements d’achat, sans avoir d’idée préconçue de ces groupes.
Détection de fraudes : Repérer des transactions bancaires inhabituelles en comparant des schémas de comportement classiques avec des anomalies, sans avoir de cas de fraude clairement identifiés au départ.
Quelques Modèles d’apprentissage non supervisé :
Clustering K-means : Regroupe les données en un certain nombre de clusters ou groupes, basés sur la similarité.
Algorithmes de réduction de dimensionnalité (PCA) : Réduit le nombre de variables dans un ensemble de données tout en conservant ses caractéristiques essentielles.
Modèles de mélange gaussien (GMM) : Estime la distribution de données en supposant qu’elles sont issues de plusieurs distributions gaussiennes.
Troisième chemin : L’apprentissage semi-supervisé
Ce chemin est mystérieux, un équilibre délicat entre guidance et exploration. Imagine un apprenti sorcier qui reçoit des indices seulement de temps en temps. Parfois, il sait ce qu’il fait, avec des exemples étiquetés pour l’aider, mais d’autres fois, il doit s’aventurer seul et trouver des réponses par lui-même.
L’apprentissage semi-supervisé est utilisé lorsqu’il est coûteux ou difficile d’obtenir des données étiquetées pour tout, mais que certaines informations sont disponibles. C’est un mélange entre l’apprentissage supervisé et non supervisé : certaines données sont étiquetées, d’autres ne le sont pas. L’algorithme apprend alors à partir de ces deux types de données pour maximiser son efficacité.
Exemples concrets :
Classification d’images : Vous avez un grand ensemble de photos de fleurs, mais seulement une petite partie est correctement étiquetée (rose, tulipe, tournesol, etc.). Le reste est inconnu, mais l’algorithme utilise ce mélange pour apprendre à classer les images.
Reconnaissance vocale : Lorsqu’un algorithme reçoit quelques enregistrements audio étiquetés avec leurs transcriptions exactes, mais qu’il doit apprendre à reconnaître les mots dans d’autres enregistrements non étiquetés.
Quelques Modèles d’apprentissage semi-supervisé :
Self-training : L’algorithme commence par entraîner un modèle sur les données étiquetées, puis utilise ce modèle pour prédire les étiquettes des données non étiquetées, en réitérant ce processus.
Co-training : Deux modèles sont formés sur des vues différentes des données et s’enseignent mutuellement en partageant leurs prédictions sur les données non étiquetées.
Transductive SVM (Support Vector Machine) : Spécifique à l’apprentissage semi-supervisé, ce modèle essaie d’optimiser à la fois la classification des données étiquetées et non étiquetées
Conclusion : Le choix du chemin
Dans l’univers fascinant du machine learning, chaque chemin, qu’il soit supervisé, non supervisé ou semi-supervisé, offre des approches uniques pour découvrir les trésors cachés dans les données. Les magiciens modernes des données, que l’on appelle souvent les data scientists, utilisent ces méthodes pour résoudre des problèmes allant de la reconnaissance d’images à la prédiction de tendances.
Mais ne vous y trompez pas, maîtriser ces chemins demande du temps, de l’expérimentation, et beaucoup d’entraînement avec vos artefacts magiques — les algorithmes. Cependant, une fois que vous saurez lequel utiliser, vous deviendrez le maître de votre propre royaume de données, capable de prédire, de classifier et de transformer des énigmes apparemment insolubles en solutions élégantes.
Alors, quel chemin choisirez-vous ? Le guide strict et structuré de l’apprentissage supervisé, l’exploration audacieuse de l’apprentissage non supervisé ou l’équilibre subtil de l’apprentissage semi-supervisé ?
Un dernier mot avant de plier la carte
Dans ce voyage à travers les sentiers du Machine Learning supervisé, vous avez appris à utiliser les indices et à laisser les données vous guider. Mais ce n’est que le début ! Chaque chemin que vous empruntez dévoilera de nouveaux secrets et mystères à explorer. Continuez à affiner vos sorts et à pratiquer, car chaque nouvelle expérience renforce votre magie de data scientist.
La Magie Continue
Cours de Machine Learning d’Andrew Ng sur Coursera : Parfait pour approfondir les fondations du ML
Kaggle : Relevez des défis concrets et mettez en pratique vos connaissances en machine learning
Dans cette aventure enchantée, que chaque algorithme que vous maîtrisez soit une clé ouvrant les portes de la connaissance, un guide vers des trésors cachés dans les données ou un moyen de tisser de nouvelles magies avec le monde des chiffres. À vous de jouer, jeunes enchanteurs des données !
À bientôt pour de nouvelles découvertes magiques !
Magiquement vôtre,
M.Royce